Vibe Coding: What It Is and How to Measure It (2026)
June 25, 2026
Reza Vatani
11 min read

Vibe coding is the practice of building software by describing what you want in natural language and letting an AI write the code, often shipping the output without reading every line. The term comes from Andrej Karpathy in early 2025, and in 2026 it shows up in real engineering orgs, not just weekend demos. At Abloomify we care about the part most teams skip measuring: how much of a pull request the AI actually wrote, and whether that code ships value or just more to review.
Key Takeaways
Q: What is vibe coding in one sentence?
A: Vibe coding is generating software by prompting an AI (Cursor, Claude Code, GitHub Copilot) and accepting the output with minimal hand-editing. Andrej Karpathy coined the term in 2025. It is fast for prototypes and risky for production, because the code runs before anyone has decided whether it is correct.
Q: Why does vibe coding fail in production?
A: It fails when AI output gets merged into core systems without the review and testing that human code gets. The result looks finished, so the discipline drops. The bill arrives later as code churn, change-failure rate, and slower reviews. The AI is rarely the problem. The missing engineering process is.
Q: How do you measure vibe coding?
A: Tie AI usage to delivery output. Abloomify separates human from AI agent contribution across code and reviews, then trends PR cycle time, code churn, review latency, and change-failure rate from GitHub and Jira. That turns "are we shipping faster or just generating more?" into a number you can defend.
Q: Should engineering leaders allow vibe coding?
A: Yes, with guardrails. Let it run free on prototypes, spikes, and internal tools where being wrong is cheap. Require human ownership and review for anything touching money, data, or security. The boundary is risk, not enthusiasm.
What is vibe coding?
Vibe coding is software development where you describe the outcome you want in plain language and let an AI coding tool produce the implementation, then accept it largely as-is. Andrej Karpathy named it in February 2025, describing a flow where you "give in to the vibes" and barely look at the code. The tools doing the work are the ones engineers already use: Cursor, Claude Code, GitHub Copilot, and the agentic modes now built into most of them. What changed in 2026 is the share of real output that starts this way. Part of nearly every pull request on a modern team now comes from a model. That makes vibe coding less of a novelty and more of a default behavior worth understanding, because the same prompt-and-accept loop that builds a demo in ten minutes can also push unreviewed logic into a billing system.
The useful distinction is between vibe coding and disciplined AI coding tools use. Both lean on the same models. The difference is who owns the result.
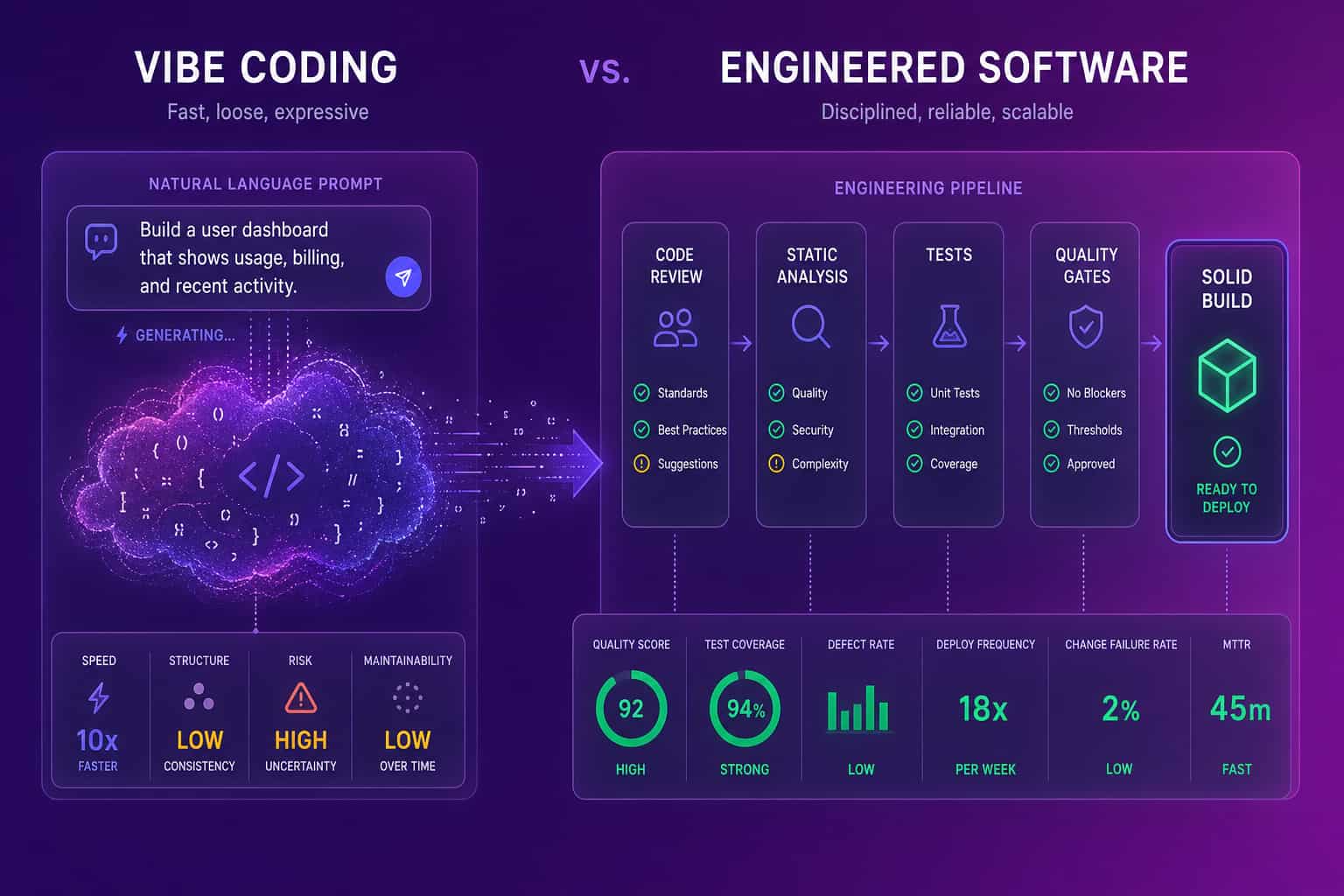
Why vibe coding took off in 2026
Vibe coding spread because the models got good enough to produce running code from a vague prompt, and because the cost of trying dropped to near zero. An engineer can now stand up a working app, a script, or a UI in the time it used to take to read the docs. That speed is real, and it is why we switched our own stack toward AI-native tools early. When we moved from GitHub Copilot to Cursor at Abloomify, the change in how fast we could prototype was obvious within a week. The pull toward vibe coding is the same pull, scaled to a whole industry: faster feedback, less boilerplate, more time on the interesting parts.
The catch is that speed of generation is not the same as speed of delivery. Generating code is now cheap. Reviewing it, testing it, and owning it in production are not. Here is the founder caution worth keeping in mind: LLMs are very good at making you feel confident about a decision that is actually wrong. A model will produce something plausible, the tests it wrote will pass, and the whole thing will feel finished. Feeling finished and being correct are different states, and only one of them survives contact with real users.
Where vibe coding works and where it breaks
Vibe coding works best where the blast radius of being wrong is small, and it breaks where the blast radius is large. Prototypes, internal tools, demos, and one-off scripts are ideal: you want the answer fast, the stakes are low, and if the code is ugly or fragile it does not matter because it will be thrown away or rewritten. Production systems that touch money, customer data, authentication, or compliance are the opposite. There, "it runs" is the start of the work, not the end. The table below is the boundary we use, and it tracks the difference the SERP keeps surfacing: vibe coding is not the same thing as AI-assisted engineering.
| Vibe coding | AI-assisted engineering | |
|---|---|---|
| Who drives | The prompt; you accept output you may not read | The engineer; AI drafts, the human owns |
| Review standard | Often skipped or skimmed | Same bar as hand-written code |
| Best for | Prototypes, demos, spikes, internal tools | Production systems and shared code |
| Main risk | Unreviewed logic in core paths | Slower if the AI output is low quality |
| What to measure | AI-vs-human split, churn, change-failure | PR cycle time, review health, AI ROI |
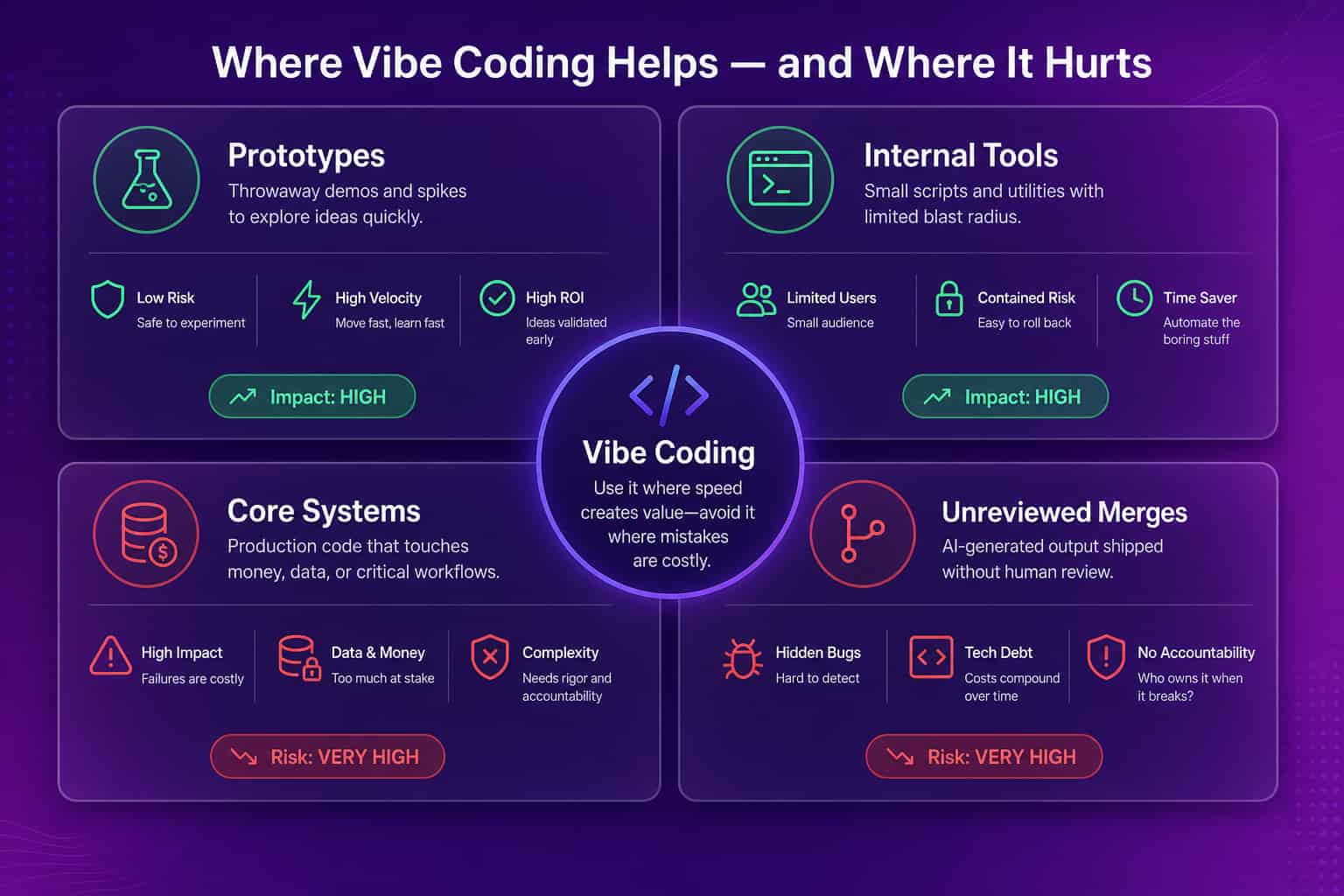
Why vibe coding "fails": the review and debt tax
When people say vibe coding failed, what usually broke is the engineering process around it, not the model. AI-generated code that merges without real review does not disappear; it becomes technical debt that charges interest on every future change. The symptoms are measurable. Code churn climbs as the same files get rewritten weeks after they shipped. Change-failure rate rises because logic nobody fully understood breaks in production. Review latency grows because senior engineers become a bottleneck, hand-checking volumes of machine output. None of these show up on the day you merge. They show up a sprint or two later, when velocity has quietly dropped and nobody can point to a single cause. This is the same trap AI code review is meant to catch, but tools only help if the team treats AI output as a draft, not a verdict.
The honest framing for leadership is this: vibe coding moves work from writing to reviewing. If you do not staff and measure the review side, the savings on the writing side are a loan, not a gift.
How to measure vibe coding
You measure vibe coding by tying AI usage to delivery outcomes, not by counting prompts or accepted suggestions. The first question is contribution: how much of the codebase and how many reviews came from a human versus an AI agent? Abloomify separates human versus AI agent contribution across code and reviews, so the split stops being a guess. The second question is whether that contribution helps. You watch the signals below, trended from GitHub and Jira, and you compare heavy AI adopters against the rest of the team. Do the teams leaning hardest on generation actually ship more and review faster, or are they just producing more code for everyone else to check? That is the difference between AI tool ROI and AI tool spend.

The signals that matter most:
- AI-vs-human contribution split across code and reviews, by team
- PR cycle time and time to first review (is generation creating a review backlog?)
- Code churn and rework within three weeks of merge
- Change-failure rate, the DORA signal that exposes fragile merges
- Test coverage on AI-generated paths, the safety net that makes speed safe
A 50-person SaaS customer of ours validated this approach the hard way. Their COO had been tracking engineering effort in a spreadsheet by hand. When they connected GitHub and our device insights, the numbers matched their manual analysis, which is what made them trust the automated view. That is the bar: data an engineering leader can verify against their own gut and their own spreadsheet. For the underlying signals, our developer productivity metrics guide goes deeper on what to trend and what to ignore.
Governing vibe coding without killing the speed
The right governance for vibe coding sets the boundary at risk, not at enthusiasm, and makes the boundary measurable. Let generation run free where being wrong is cheap: prototypes, spikes, internal tooling, throwaway demos. Require human ownership, review, and tests where being wrong is expensive: anything in a production path, anything touching money, data, identity, or compliance. Then verify the boundary held, rather than trusting that it did. Privacy-first matters here, because you can get all of this signal without reading a single line of anyone's code. Abloomify is PII-free by architecture: we analyze contribution patterns, PR timing, and delivery metrics, never the content of the code or the messages around it. Engineers accept fair, data-driven measurement far more readily than surveillance, and there is no evidence that watching screens improves output anyway.
Vibe coding is not going away, and pretending it is would be its own kind of denial. The teams that win with it will not be the ones that generate the most code. They will be the ones that can tell, in a number, whether the code is worth keeping. Generate freely. Measure honestly.
FAQ
What exactly is vibe coding?
Vibe coding is building software by describing what you want in natural language and letting an AI tool like Cursor, Claude Code, or GitHub Copilot write the code, often accepting the output without reading every line. Andrej Karpathy coined the term in early 2025. It works well for prototypes and throwaway tools and gets risky in production systems.
Why did vibe coding fail for some teams?
Vibe coding fails when AI-generated code ships into core systems without review. The model produces something that runs, so it feels finished, but nobody owns the logic. The cost shows up later as code churn, change-failure rate, and review load. The failure is rarely the AI. It is skipping the engineering discipline around it.
Is vibe coding actually good?
Vibe coding is good for speed on low-stakes work: prototypes, internal scripts, demos, and spikes where being wrong is cheap. It is a poor fit for production code that touches money, data, or security. The useful question is not whether vibe coding is good, but whether it ships value you can measure or just more code to review.
How is vibe coding different from AI-assisted engineering?
In vibe coding the prompt drives and you accept output you may not fully read. In AI-assisted engineering the engineer drives, AI drafts, and a human owns and reviews the result to the same standard as hand-written code. Same tools, different discipline. The second one is what holds up in production. For the tool side of that choice, see our Copilot vs Cursor comparison.
How does Abloomify help measure vibe coding?
Abloomify connects to GitHub, Jira, and AI tools like Cursor, Claude Code, and GitHub Copilot to separate human contribution from AI agent contribution and correlate AI usage with delivery output. It trends PR cycle time, code churn, review health, and change-failure rate so AI-generated code becomes a measurable signal. It does this without hurting morale, and it is PII-free by architecture.
Reza Vatani
Co-Founder & CAIO
AI-driven entrepreneur with a strong background in robotics and advanced analytics. PhD from Old Dominion University and former Product Development leader at Nasdaq Verafin.