Developer Productivity Metrics: What to Measure in 2026
June 1, 2026
Reza Vatani
10 min read

Developer productivity metrics are the signals engineering leaders use to tell whether a team is shipping, where work bottlenecks, and whether tools like Cursor and GitHub Copilot are actually helping. Most teams measure the wrong things. They count commits and hours, then wonder why the numbers do not match what they feel on the ground. The 50-person SaaS team that first validated Abloomify's engineering data against a manual spreadsheet found the opposite problem worth having: the data matched reality, so they could finally trust it.
Key Takeaways
Q: What are developer productivity metrics?
A: Developer productivity metrics are quantitative signals about how engineering work flows from idea to production. The useful ones are delivery-oriented and team-level, such as PR cycle time, deployment frequency, and review health. Abloomify reads them from GitHub, Jira, and Linear without reading code content.
Q: Which developer productivity metrics actually matter?
A: PR cycle time, deployment frequency, change failure rate, review wait time, and focus time. These tie to outcomes a leader can act on. Lines of code, commit counts, and hours logged measure activity, not output, and they reward the wrong behavior.
Q: How do AI coding tools change developer productivity measurement?
A: They add a new question: how much of the output is human and how much is the agent? Abloomify separates human from AI agent contribution across tasks, code, and reviews, then correlates Cursor, Claude Code, and Copilot usage with delivery to show real ROI.
Q: Can you measure developer productivity without monitoring engineers?
A: Yes. Abloomify uses API connections and PII-free signals, so there are no screenshots, no keyloggers, and no screen recording. You measure how work moves, not what a person typed or read.
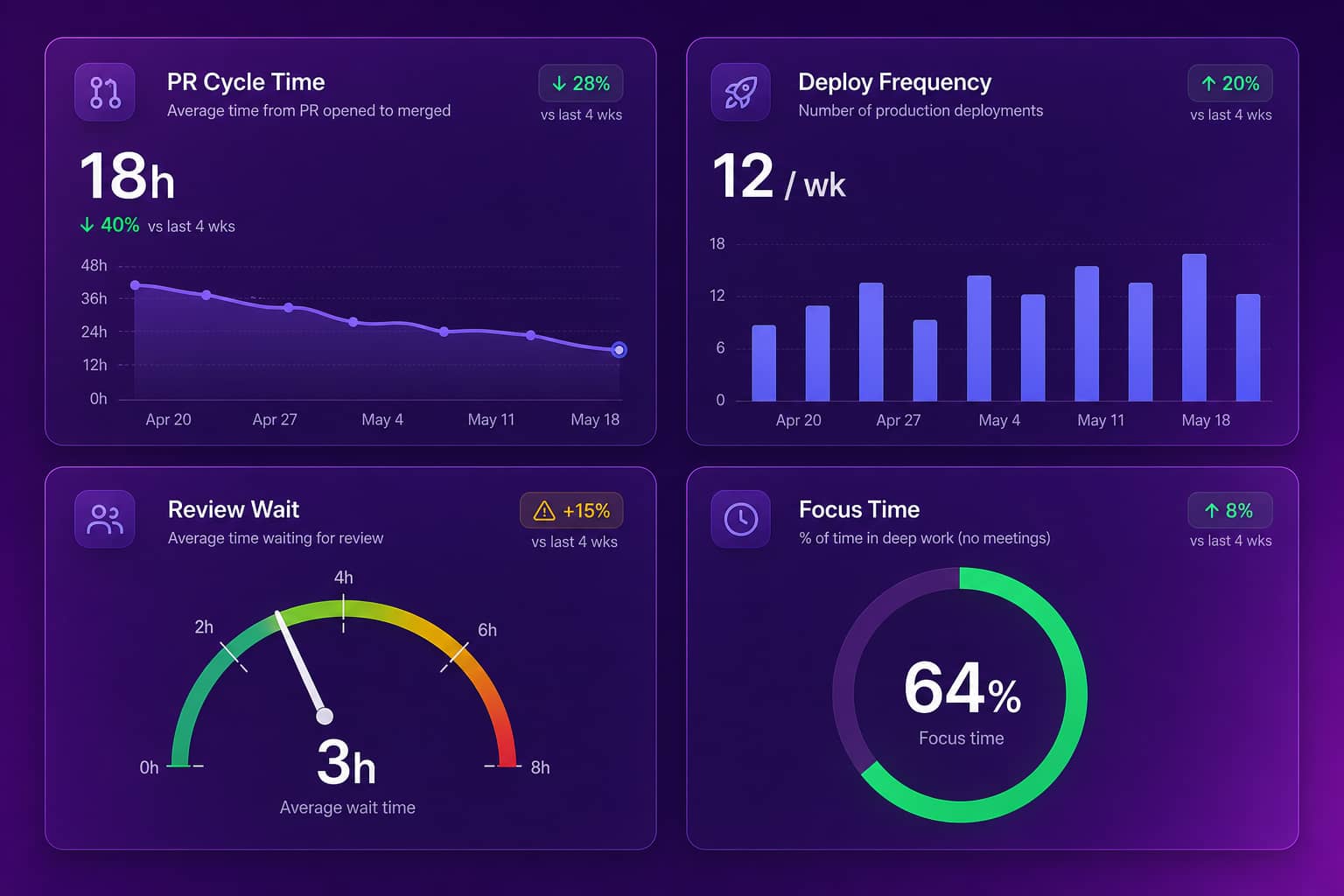
What are developer productivity metrics?
Developer productivity metrics are quantitative signals that describe how engineering work moves from a first commit to running code in production. The good ones answer questions a VP of Engineering actually asks on a Monday: where are PRs stuck, is the team shipping faster or slower than last quarter, and is review load fair. They live at the team level, because individual scorecards turn into surveillance and gaming fast. They draw on data engineers already generate in GitHub, Jira, and Linear, so collecting them costs no extra effort. A useful metric changes a decision. If a number goes up or down and nobody does anything differently, it is decoration, not a metric.
There is a quiet trap here. The metrics that are easiest to count are usually the least useful, and the ones that matter most take a little work to assemble across tools. That gap is where most engineering dashboards fail.
The developer productivity metrics worth tracking
The developer productivity metrics worth tracking share one trait: they connect to delivery outcomes you can influence this sprint. PR cycle time, the span from first commit to merge, is the single best proxy for delivery velocity, and a median above 48 hours almost always points to a review bottleneck rather than slow coding. Deployment frequency shows how often value reaches users. Change failure rate keeps speed honest, because shipping fast and breaking often is not productivity. Review wait time exposes where cycle time actually leaks, usually in the hours a PR sits unclaimed. Focus time, the share of the week protected from meetings and context switching, predicts sustainable output better than any activity count. Track these as trends at the team level, not as leaderboards.
Here is the short version of what to watch and what to skip.
| Metric | What it tells you | Healthy signal |
|---|---|---|
| PR cycle time | Delivery velocity end to end | Median under 24 hours |
| Review wait time | Where cycle time leaks | First review under 4 hours |
| Deployment frequency | How often value ships | Trending up or steady |
| Change failure rate | Whether speed stays safe | Low and stable |
| Focus time | Capacity for deep work | Majority of the week |
A few of these map to the DORA delivery framework. The rest come from the daily reality of how review and meeting load shape what a team can actually finish.
The metrics that mislead (and why teams still use them)
The metrics that mislead are the ones that are trivial to count and feel objective: lines of code, commit count, story points compared across teams, and hours logged. They survive because they are convenient, not because they predict anything. Lines of code punish the engineer who deletes 400 lines of dead code and rewards the one who pads a feature. Commit counts reward many tiny commits over one clean change. Story points only carry meaning inside a single team over time, so comparing them across teams produces confident nonsense. Hours logged measure presence, which has almost nothing to do with output in knowledge work. The damage is not just inaccuracy. When you measure activity, people optimize for activity, and you get busier teams that ship less.
Avoid these as productivity signals:
- Lines of code: gameable, and it penalizes clean, concise work.
- Commit count: rewards noise over meaningful change.
- Story points across teams: only comparable within one team over time.
- Hours worked or logged in: measures presence, not delivery.
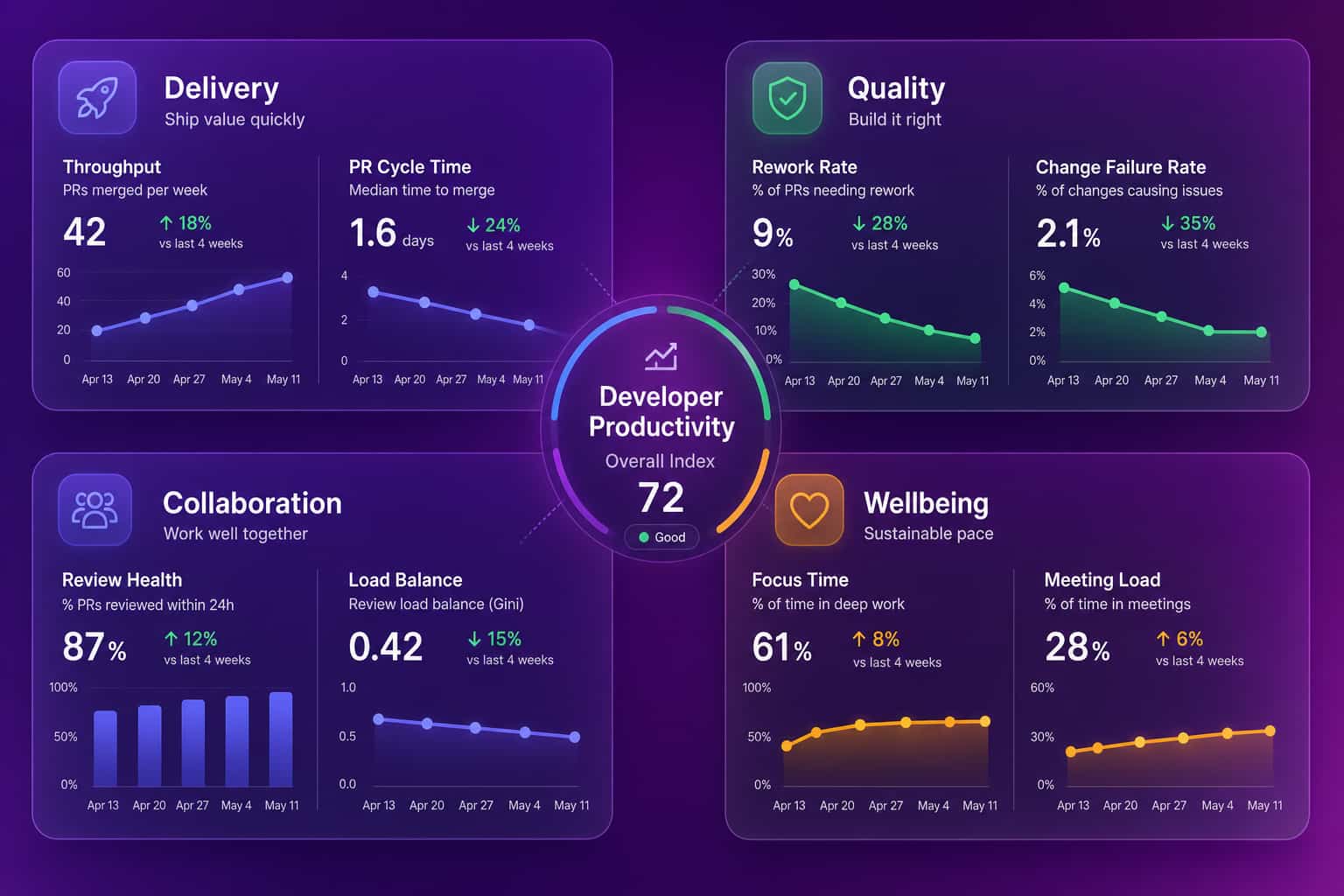
DORA, SPACE, and the limits of any single framework
DORA and SPACE are the two frameworks worth knowing, and the mistake is treating either as a complete scorecard. DORA tracks four delivery signals: deployment frequency, lead time for changes, change failure rate, and time to restore service. It is excellent for answering how fast and how safely a team ships, which is why it became the default for engineering benchmarking. SPACE is broader and deliberately resists a single number, spanning satisfaction and wellbeing, performance, activity, communication, and efficiency. SPACE exists precisely because reducing developer productivity to one metric always backfires. The practical move is to borrow the delivery rigor of DORA, add the collaboration and wellbeing lenses from SPACE, and refuse to roll it all into a single "productivity score" that executives will inevitably misread.
No framework was designed for a world where a meaningful share of code is now drafted by an agent. That is the gap worth closing next. For a deeper breakdown of the delivery side, our guide to engineering velocity metrics like PR cycle time and review health goes metric by metric.
How do you separate human from AI agent contribution?
You separate human from AI agent contribution by instrumenting the tools that produce the work, then attributing output across tasks, code, and reviews. This matters more every quarter, because "the team shipped 30 PRs" no longer means what it used to when a coding agent drafted a third of them. Abloomify imports usage signals from Cursor, Claude Code, and GitHub Copilot, correlates them with engineering output, and shows the split between human-authored and agent-assisted work. That split is the foundation of honest AI tool ROI: not how many seats you bought, but whether usage translates into faster, safer delivery. It also protects against the comfortable illusion that more AI-generated code automatically means more value, when sometimes it just means more code to review.
I spend a lot of my time on AI systems, and the failure mode I trust least is confidence without evidence. A good model is very good at making you feel sure about a decision you have not actually checked. AI coding tools are no different. A team can swear Copilot made them faster while the delivery data shows review queues growing under the extra volume. The only way to know is to measure usage against output, per team, over time. Tools like Cursor are genuinely strong, and the way to prove it is data, not vibes.
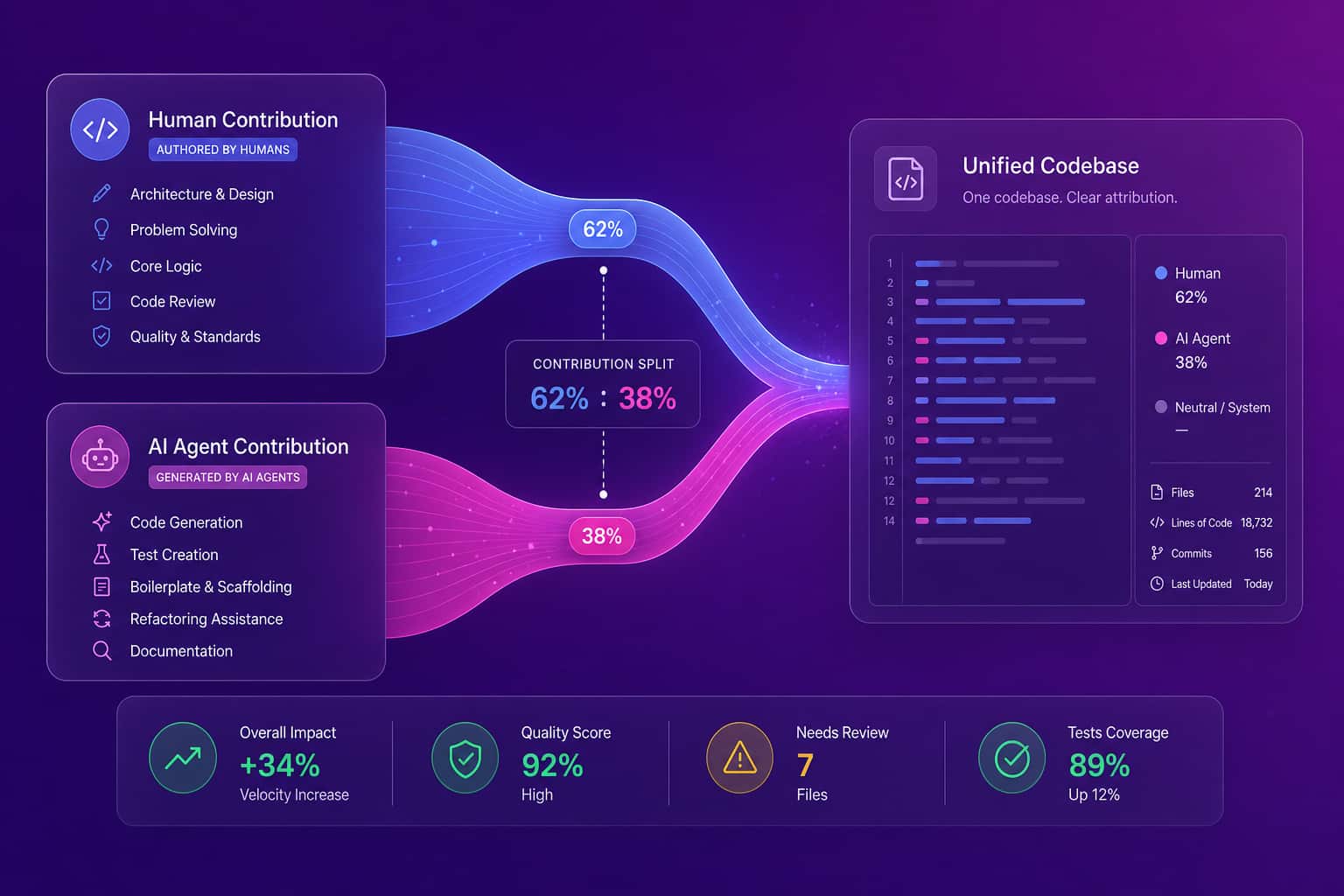
How to measure developer productivity without surveillance
You measure developer productivity without surveillance by reading work signals through APIs instead of watching screens. Abloomify connects to GitHub, Jira, Linear, and AI coding tools and analyzes how work moves: PR timing, review patterns, deployment cadence, workload balance, and contribution mix. It never reads code content, takes screenshots, logs keystrokes, or records screens. That distinction is not cosmetic. Screen-monitoring tools generate real resistance, and engineers game or resent them, while signal-based analytics measure the actual flow of delivery from systems teams already use. Privacy-first is the lead, and PII-free architecture is how we deliver it: signals about work, never content about people. The result is a fair picture that engineers can look at without feeling watched, which is the only kind of productivity data a team will trust enough to improve against.
Good metrics survive scrutiny from the people they describe. Bad metrics get gamed. If your engineers would be uncomfortable seeing how a number is collected, it is the wrong number. You can see the same signals across delivery, review health, and workload in our engineering productivity analytics, built for engineering leaders who want clarity without a monitoring agent on every laptop.
FAQ
What are the best developer productivity metrics to track?
The most useful developer productivity metrics are delivery-oriented and team-level: PR cycle time, deployment frequency, change failure rate, review wait time, and focus time. They tie to outcomes a leader can act on. Abloomify reads these from GitHub, Jira, and Linear without reading code content or installing screen monitoring.
Are lines of code a good productivity metric?
No. Lines of code, commit counts, and hours logged measure activity, not output. They are easy to game and they punish clean, concise work. An engineer who deletes 400 lines of dead code looks unproductive on these metrics while making the system healthier. Measure how work flows, not how much gets typed.
How do DORA and SPACE metrics differ?
DORA measures delivery performance through four signals: deployment frequency, lead time for changes, change failure rate, and time to restore service. SPACE is broader, covering satisfaction, performance, activity, communication, and efficiency. DORA tells you how fast and safely you ship. SPACE reminds you that developer productivity is never a single number.
Can you measure developer productivity without surveillance?
Yes. Abloomify connects to GitHub, Jira, Linear, and AI coding tools through APIs and reads work signals, not content. No screenshots, no keyloggers, no screen recording. You get PR cycle time, review health, workload balance, and human vs AI agent contribution from data engineers already produce, with PII-free architecture by design.
How do you measure the ROI of AI coding tools like Cursor or Copilot?
Tie usage to output. Abloomify imports usage signals from Cursor, Claude Code, and GitHub Copilot, then correlates them with engineering output such as PR cycle time and code velocity. It separates human from AI agent contribution, so you can see whether the spend actually produces faster, safer delivery instead of just more code to review.
Reza Vatani
Co-Founder & CAIO
AI-driven entrepreneur with a strong background in robotics and advanced analytics. PhD from Old Dominion University and former Product Development leader at Nasdaq Verafin.