AI Code Review: What It Is and How to Know It Works
June 18, 2026
Reza Vatani
11 min read

AI code review uses a model to read a pull request and leave review comments before a human does. In 2026 it is everywhere: CodeRabbit, GitHub Copilot, Greptile, and Qodo all ship it, and most engineering teams have at least tried one. The harder question is whether it actually makes your team faster or just adds more comments to read. Abloomify exists to answer that with delivery data, not vibes.
Key Takeaways
Q: What is AI code review?
A: AI code review is an automated first pass where a large language model reads a pull request diff, flags likely bugs, missing tests, security risks, and style issues, and posts inline comments. Tools like CodeRabbit, Greptile, and GitHub Copilot run this on every PR before a human opens it.
Q: Does AI code review replace human reviewers?
A: No. AI handles the mechanical pass (null checks, obvious bugs, style) well, but it misses architecture, business logic, and intent. Human reviewers still own final approval. The useful framing is AI as a fast first reviewer, with humans deciding what ships.
Q: Do AI code review tools actually make teams faster?
A: Sometimes. A 2025 METR study found experienced developers on familiar codebases were slower with AI tools even though they felt faster. The only way to know for your team is to track PR cycle time and rework before and after rollout, which Abloomify does.
Q: How does Abloomify fit with AI code review?
A: Abloomify does not review code. It measures whether your AI code review investment pays off by correlating tool usage with PR cycle time, review depth, and rework, and separating human from AI agent contribution, all PII-free with no code content stored.
What is AI code review?
AI code review is the practice of having a large language model read a pull request and leave review feedback automatically, before or alongside a human reviewer. The model ingests the diff, the surrounding files, and sometimes the linked issue, then posts inline comments on likely bugs, missing tests, security risks, style violations, and risky changes. It runs on every pull request without waiting for a teammate to free up, which is why teams reach for it when review latency is the bottleneck. Common 2026 tools include CodeRabbit, Greptile, Qodo, GitHub Copilot code review, and GitLab Duo. None of them merge code on their own. They produce a first-pass review that a human still has to read, accept, or override. The value is speed and coverage on the mechanical parts of review, not judgment about whether the change is the right one to make.
Think of it as a tireless junior reviewer who reads every line in seconds and never gets bored. That is genuinely useful. It is also why the failure mode is so easy to miss: a junior reviewer who comments on everything can feel productive while burying the one comment that mattered.
How does AI code review work?
AI code review works by feeding the pull request into a model with enough context to reason about the change, then converting the model's output into structured review comments. A typical tool pulls the diff, retrieves related files and prior review history, builds a prompt, and asks the model to identify defects, suggest fixes, and rate the risk of each file. Better tools add static analysis, run linters and tests, and ground the model in your codebase so it stops inventing problems that do not exist. The output lands as inline comments on the PR, a summary at the top, and sometimes a suggested patch you can accept with one click. The whole loop runs in seconds to a couple of minutes, which is the entire point. The first review happens immediately instead of sitting in a queue while a senior engineer finishes their own work.
The grounding step is what separates a useful tool from a noisy one. A model with no repo context flags imaginary issues and misses real ones. A model with retrieval over your codebase, your conventions, and your past reviews comments like someone who has actually worked in the repo.
What AI code review catches, and what it misses
AI code review is strong on the mechanical layer of review and weak on the judgment layer, and knowing the line between them is how you use it well. It reliably catches the things humans find tedious: null pointer risks, unhandled errors, missing test coverage, inconsistent naming, obvious security issues like hardcoded secrets, and small logic mistakes inside a single function. It struggles with the things that actually break systems: whether the architecture is right, whether the change matches the business requirement, whether a refactor introduces a subtle race condition across services, and whether this feature should exist at all. It also generates noise. On a large pull request, an AI reviewer can leave dozens of low-value comments that bury the two that matter, which slows review down instead of speeding it up. Treat the AI pass as triage, not as the decision.
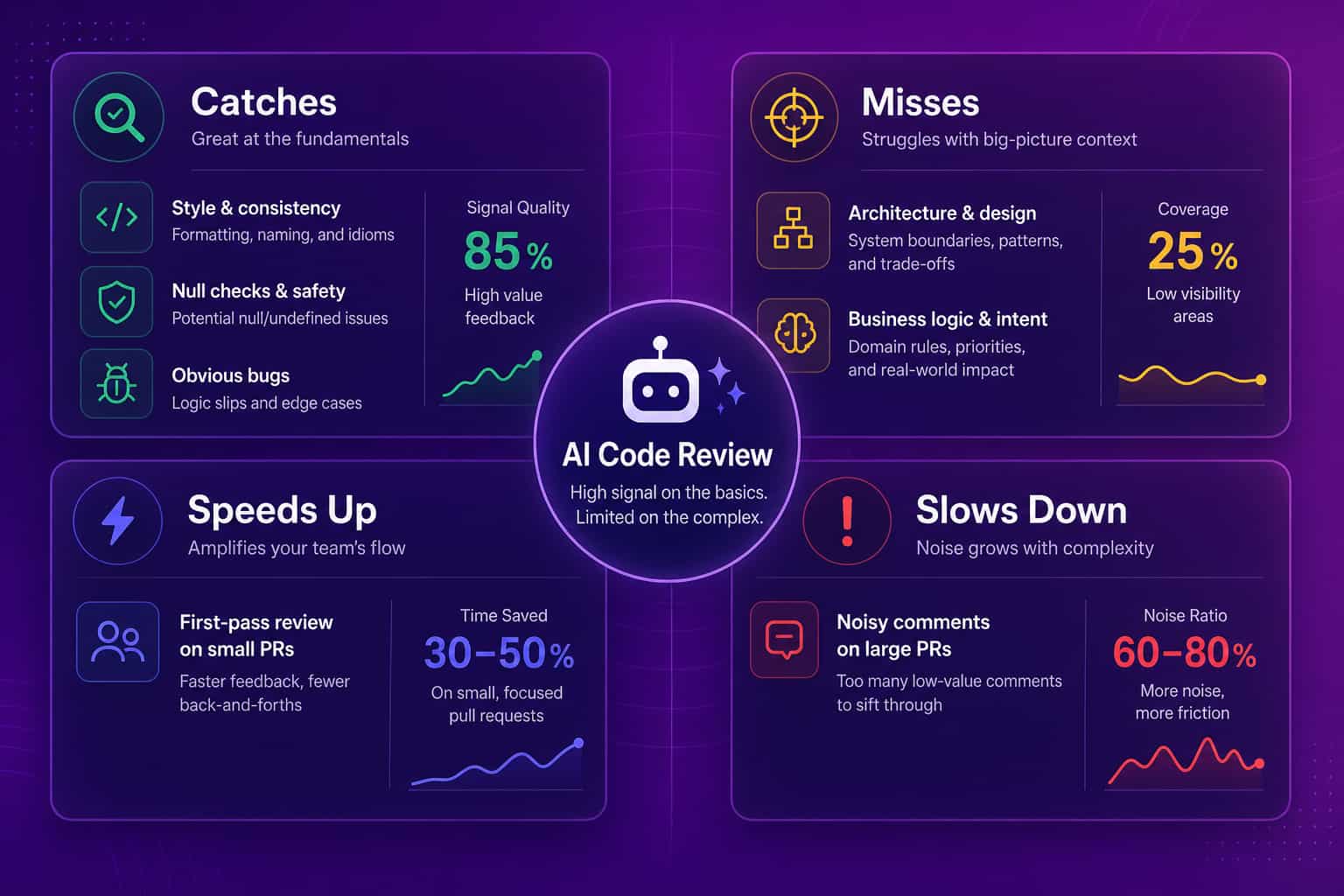
This is also why small pull requests are the unlock. AI review quality drops as the diff grows, the same way human review does. Teams that already keep PRs small get the most out of AI review, and teams that ship giant diffs mostly get more noise. If review is your bottleneck, the fix usually starts with code review cycle time and PR size, not with adding another bot.
The AI code review tools landscape in 2026
The AI code review market in 2026 splits into dedicated review tools, platform-native features, and broader AI coding assistants that added review on top. Dedicated tools like CodeRabbit, Greptile, and Qodo focus entirely on the review experience and tend to lead on depth and codebase grounding. Platform-native options like GitHub Copilot code review and GitLab Duo win on convenience because the review shows up where your team already works, with nothing extra to install. Assistant-first tools like Cursor and Claude Code can review code too, though review is a side capability rather than their core. There is no single best tool. The right pick depends on where your code lives, how much review noise your team will tolerate, and, most importantly, whether the tool moves your delivery numbers once it is turned on.
| Tool | Category | Best for |
|---|---|---|
| CodeRabbit | Dedicated reviewer | Deep PR summaries and inline review on every change |
| Greptile | Dedicated reviewer | Codebase-grounded review across many files |
| Qodo | Dedicated reviewer | Review paired with test generation |
| GitHub Copilot code review | Platform-native | Teams standardized on GitHub |
| GitLab Duo | Platform-native | GitLab-native pipelines and review |
| Cursor, Claude Code | Assistant-first | Editor-driven review alongside authoring |
Abloomify is not on this list because Abloomify does not review code. It connects to all of these as data sources. If you want a deeper read on the assistants behind several of these features, Copilot vs Cursor and AI coding tools go further.
How to measure whether AI code review is working
The only honest test of AI code review is whether your delivery numbers improve after you turn it on, and most teams never check. The metrics that matter are pull request cycle time (open to merge), review depth (are humans still engaging or just rubber-stamping the AI), rework rate (how often merged code gets fixed again within a week or two), and escaped defects (bugs that reach production). If cycle time drops and rework stays flat, the tool is helping. If cycle time drops but rework climbs, you have traded review speed for production pain, which is a worse deal than the slow review you started with. The trap is that AI review feels productive because there is more activity on every PR. Activity is not delivery. You need a before-and-after view of the actual outcomes, segmented by team, to tell the real wins apart from the theater.
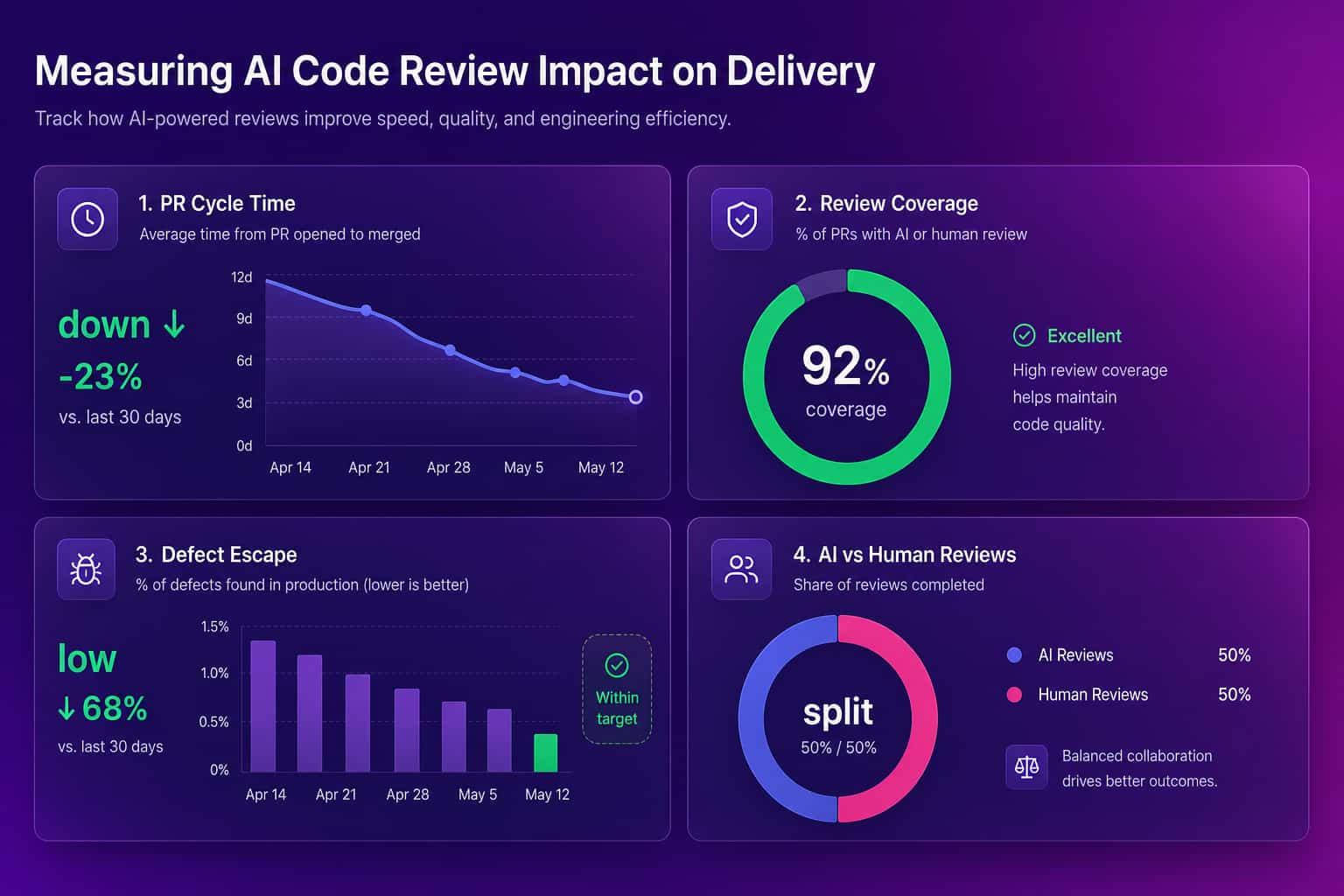
The wider research should keep you honest here. Google's DORA program has linked rising AI adoption to gains in throughput while warning about pressure on delivery stability, and a 2025 METR study found experienced developers working in familiar codebases were actually slower with AI tools, even though they reported feeling faster. The lesson is not that AI review is bad. The lesson is that perceived speed and real speed diverge, so you have to measure.
Who wrote the code: separating human and AI contribution
As AI writes more of the code and reviews more of the pull requests, the question every engineering leader will face is simple and uncomfortable: who actually did this work. When an agent drafts a change, another AI reviews it, and a human clicks approve, the commit history says the human did everything. That is fine until you are trying to justify an AI tool budget, calibrate a performance review, or understand why velocity went up but quality went sideways. You need to see the split. Abloomify imports usage from Cursor, Claude Code, and GitHub Copilot, connects it to GitHub and GitLab delivery data, and separates human from AI agent contribution across tasks, code, and reviews, PII-free, with no code content stored. The point is not to police engineers. It is to make sure the credit, the budget, and the quality conversation are all grounded in what really happened.
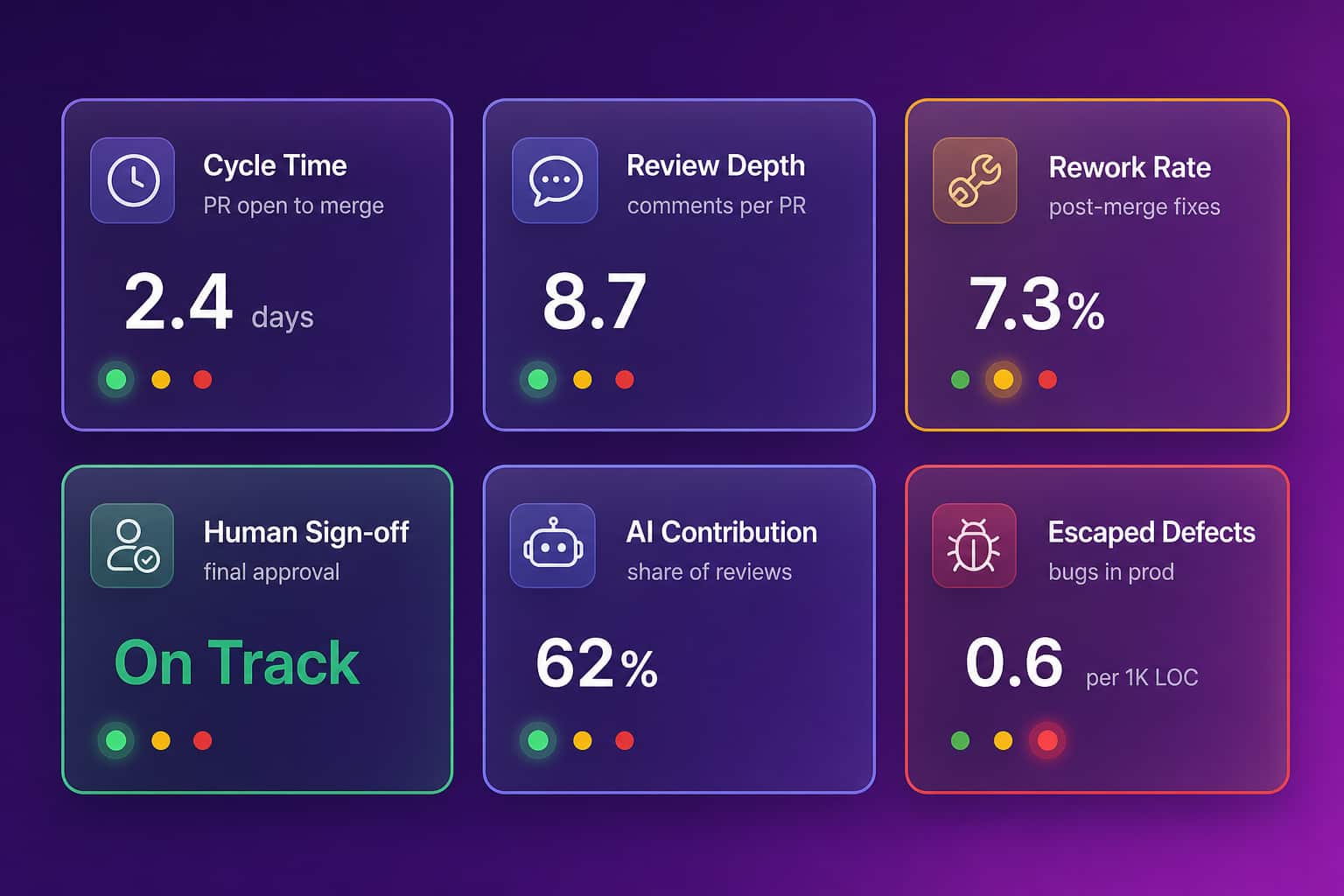
This is the same approach Abloomify takes to engineering velocity generally: outcomes from the systems where work already happens, not surveillance. See engineering productivity analytics for how the delivery side fits together.
AI can write the code. AI can review the code. Knowing whether any of it made you faster is still a measurement problem, and that is the part you cannot hand to a model.
FAQ
What is AI code review?
AI code review is an automated first pass where a large language model reads a pull request diff and posts inline comments on likely bugs, missing tests, security risks, and style issues before a human reviewer opens the PR. CodeRabbit, Greptile, Qodo, GitHub Copilot, and GitLab Duo all do this in 2026.
Can AI code review replace human reviewers?
No. AI is strong on the mechanical layer (null checks, obvious bugs, style, missing tests) and weak on judgment (architecture, business logic, intent). Humans still own final approval. The best teams use AI as a fast triage pass so human reviewers spend their attention on the decisions that actually matter.
Is AI code review safe for proprietary code?
It depends on the tool. Some send your diffs to a third-party model API, so check the data handling and retention terms. Abloomify avoids the question entirely: it does not read or store code content. It connects to GitHub and GitLab for delivery signals only, PII-free, so you can measure AI review impact without exposing source.
What are the best AI code review tools in 2026?
There is no single best. CodeRabbit, Greptile, and Qodo lead among dedicated reviewers, GitHub Copilot code review and GitLab Duo win on platform convenience, and Cursor and Claude Code review as a side capability. The right pick is whichever one moves your PR cycle time and rework once you turn it on.
How do you measure the ROI of AI code review?
Track PR cycle time, review depth, rework rate, and escaped defects before and after rollout, segmented by team. If cycle time drops and rework stays flat, it is paying off. Abloomify correlates AI tool usage with these delivery outcomes and separates human from AI agent contribution, so a seat count becomes a defensible number.
Reza Vatani
Co-Founder & CAIO
AI-driven entrepreneur with a strong background in robotics and advanced analytics. PhD from Old Dominion University and former Product Development leader at Nasdaq Verafin.