Agentic AI Coding Tools: A 2026 Guide for Eng Leaders
June 12, 2026
Reza Vatani
11 min read

Agentic AI coding tools changed the AI coding market the most in 2026. Instead of suggesting the next line, they take an instruction, plan the work, edit across files, run tests, and open a pull request while the engineer watches. The shift is real, and it creates a new problem for engineering leaders: when an agent writes the code and a human ships it, who did the work? Abloomify was built to answer that with data.
Key Takeaways
Q: What are agentic AI coding tools?
A: They are AI coding tools that act, not just suggest. An agent reads context, plans a change, edits multiple files, runs tests, and often opens a pull request from one prompt. Cursor, Claude Code, GitHub Copilot agent mode, and Devin are the common examples engineering teams run in 2026.
Q: How are they different from autocomplete?
A: Autocomplete finishes a line while a human stays in the driver seat. An agent takes the wheel across the whole task. That moves a larger share of authoring from the human to the model, which is exactly why separating human from AI agent contribution stops being optional.
Q: What is the best agentic coding tool?
A: There is no single winner. Cursor and Claude Code lead on in-editor agentic edits, Copilot agent mode wins on GitHub-native flows, and async agents like Devin return a pull request from an issue. The best one is the one your delivery data rewards on your codebase.
Q: How do you measure if an agent is worth it?
A: Tie agent usage to engineering output. Abloomify correlates Cursor, Claude Code, and Copilot usage with PR cycle time, review wait, and rework, and separates human from AI agent contribution. That turns a license decision from a vibe into a number.
What are agentic AI coding tools?
Agentic AI coding tools are developer tools that use a large language model to plan and carry out multi-step coding work on their own, rather than suggesting one completion at a time. You give an agent an outcome ("add rate limiting to the auth service and update the tests"), and it reads the relevant files, drafts a plan, edits across the codebase, runs the test suite, reads the failures, and iterates until the change holds together, then presents a diff or opens a pull request. The defining trait is autonomy across steps. A completion tool waits for the human to drive every keystroke. An agent drives itself between checkpoints, and the human reviews the result instead of authoring it. This is a meaningful change in how engineering work gets produced, because it moves a real share of authoring and review from a person to a model. For a broader map of the whole category, including completion and codebase chat, see our guide to AI coding tools. This piece is about the agentic tier specifically.
The practical version of that definition matters more than the buzzword. An agent is worth running when the work is well-scoped, mechanical in parts, and verifiable by tests. It struggles when the task is ambiguous, when context is scattered across systems it cannot see, or when "done" is a judgment call. Treat agents as fast, tireless junior engineers who never get bored of boilerplate and never quite own the outcome.
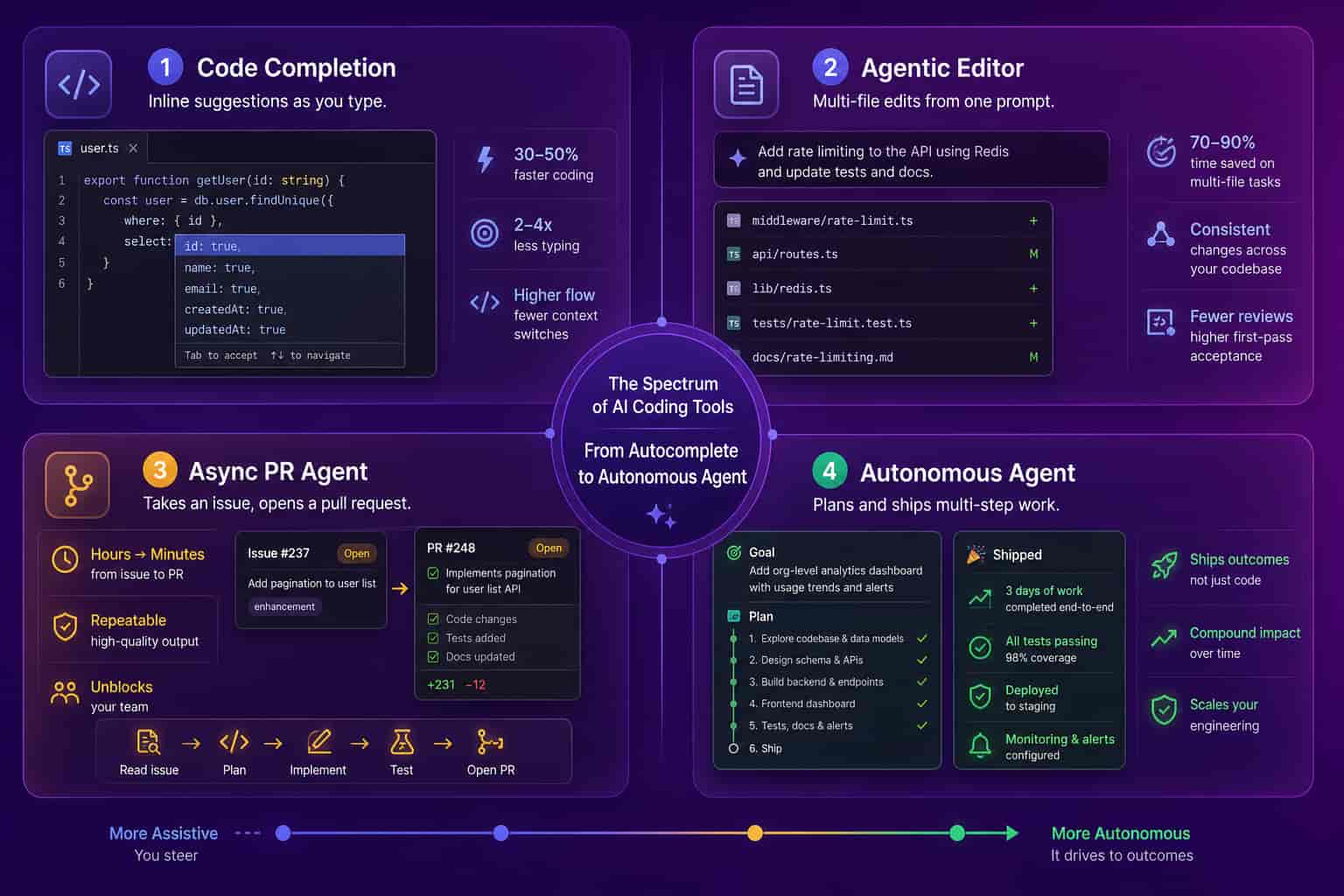
The leading agentic AI coding tools in 2026
The leading agentic AI coding tools in 2026 split into two camps: in-editor agents that work alongside you, and asynchronous agents that go off and return a pull request. In the editor, Cursor and Claude Code are the tools most teams reach for, because they hold a large codebase in context, plan a change across many files, and apply edits you can accept or reject inline. GitHub Copilot added an agent mode that does similar work while staying tight to GitHub Enterprise governance and billing, which keeps procurement friction near zero for teams already on the platform. On the asynchronous side, agents like Devin from Cognition, plus open frameworks such as OpenHands, take an issue from your tracker and hand back a draft pull request with no human in the loop until review. AI code reviewers like CodeRabbit are agentic too, just pointed at the review step rather than authoring. None of these is strictly better than the others, because they optimize for different constraints and different team shapes.
The honest way to read the market is by job, not by brand. If your engineers want speed inside their own flow, the in-editor agents win. If you want to clear a backlog of small, well-specified tickets without occupying a senior engineer, an async agent is the better fit. Our own team at Abloomify switched from Copilot to Cursor and saw a large jump in product velocity, which was one of the better tooling calls we made that year. For a closer look at that decision, see our Copilot vs Cursor comparison.
| Type | What the agent does | Example tools |
|---|---|---|
| In-editor agent | Plans and applies multi-file edits you review inline | Cursor, Claude Code |
| GitHub-native agent | Agent mode tied to GitHub workflows and governance | GitHub Copilot agent mode |
| Async PR agent | Takes an issue, returns a draft pull request | Devin, OpenHands |
| AI review agent | Reviews diffs and comments before a human does | CodeRabbit, Graphite |
The contribution problem agents create
The hardest thing agentic AI coding tools do to an engineering org is blur the line between human and machine output, and most teams have no way to see the split. When an agent drafts a change, a human edits a third of it, and the pull request merges under the human's name, your delivery data records a human contribution that was substantially machine-authored. Scale that across a team and your velocity numbers quietly stop meaning what you think they mean. A sprint that looks 30% faster might be 30% more agent-drafted code moving through the same review process, or it might be a genuine team improvement. Those are very different facts, and they lead to very different decisions about hiring, tooling spend, and who is actually growing as an engineer. Without separating human from AI agent contribution, you cannot tell the story straight, and the board question about AI ROI gets answered with a guess.
This is the capability Abloomify built specifically for the agentic era. We separate human versus AI agent contribution across tasks, code, and reviews, so the contribution mix is a measured number rather than an assumption baked into a name on a commit.
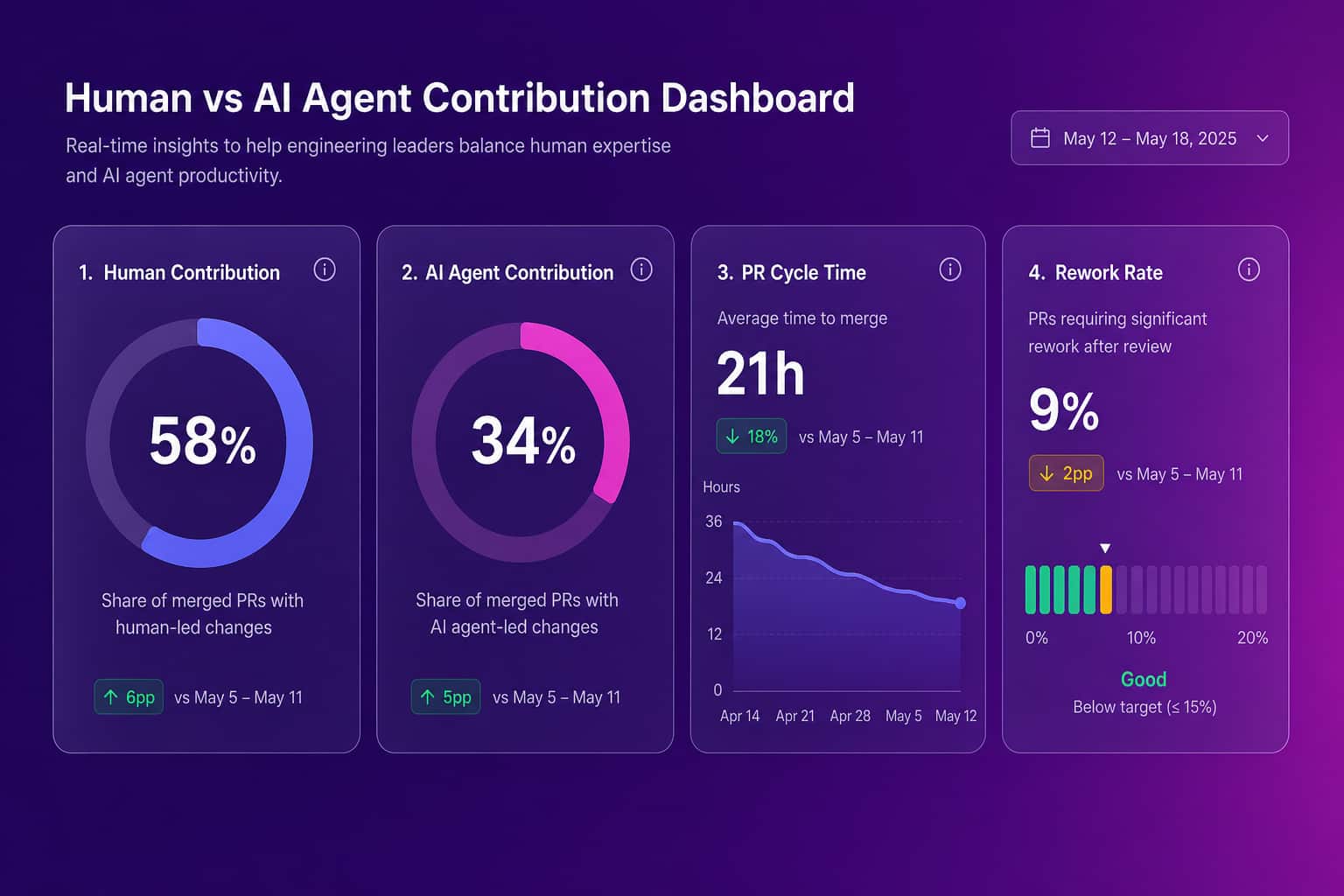
How to measure agentic AI coding tool ROI
You measure agentic AI coding tool ROI by connecting agent usage to engineering output and watching the trend after rollout, not by asking engineers whether the agent feels helpful. This is what Abloomify does. It imports usage signals from Cursor, Claude Code, and GitHub Copilot, correlates them with delivery metrics like PR cycle time, throughput, and review wait, and separates human from AI agent contribution so you can see how much of any gain is the team and how much is the tool. The analysis runs PII-free, through APIs, with no screenshots, no keyloggers, and no reading of code content, so engineers do not experience it as surveillance. The output is an adoption picture by team plus a direct answer to whether the agent spend translates into faster, safer delivery, which is the answer a VP of Engineering needs when finance asks what the AI line item bought at renewal.
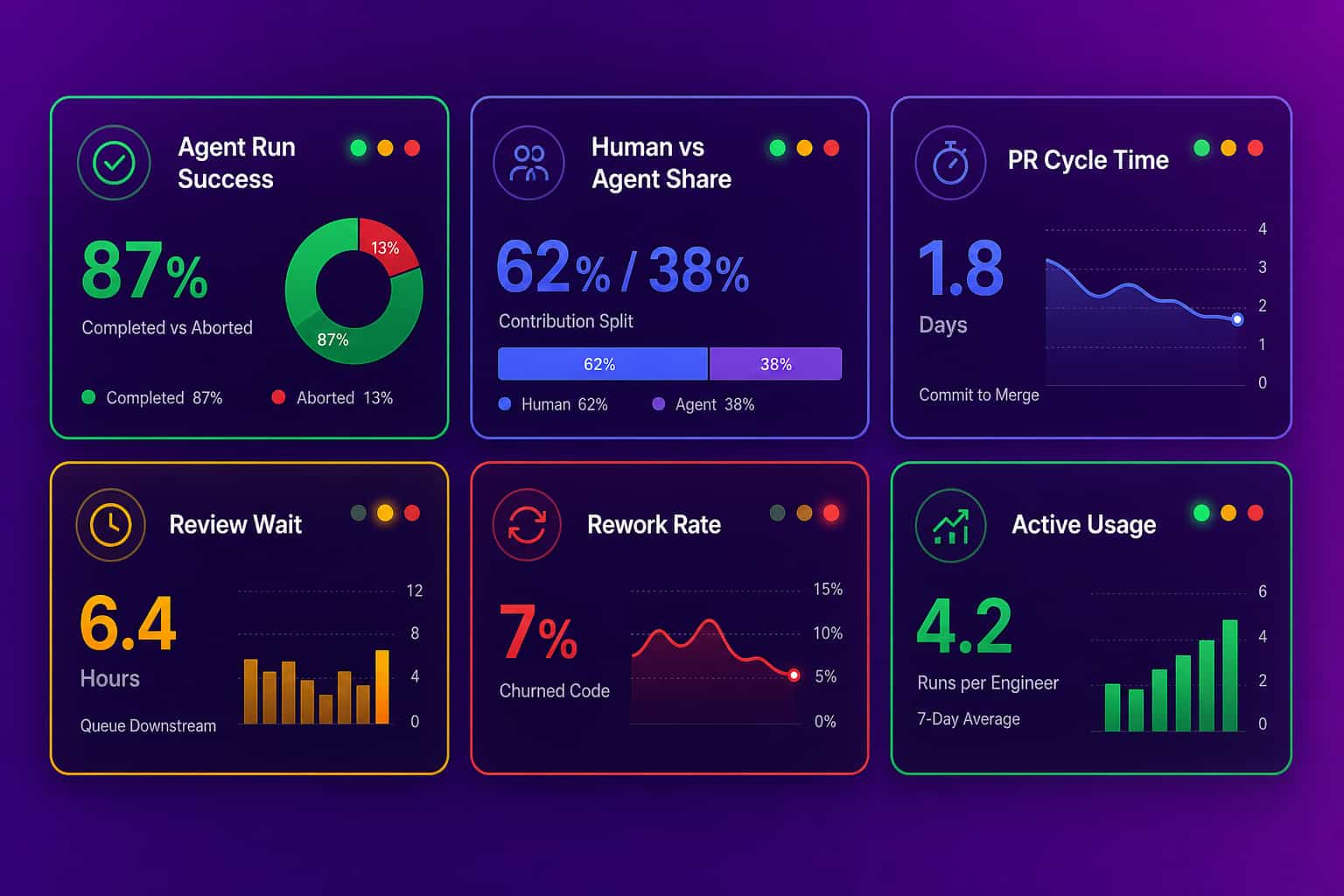
A few signals separate an agent that is earning its seat from one that is merely installed:
- Agent run success rate: how often runs complete and merge versus get abandoned mid-task.
- Human vs AI agent share: how much of the throughput is human work versus agent-drafted code.
- PR cycle time trend: first commit to merge, compared against your pre-rollout baseline.
- Review wait time: whether agent output just pushed the bottleneck downstream into review.
- Rework rate: churned or reverted code, so speed is not bought with quality debt.
For the underlying delivery signals these build on, see our guide to developer productivity metrics and DORA metrics. Abloomify pulls these through your existing GitHub integration and Cursor integration.
How to evaluate and govern agentic coding agents
Evaluate agentic coding agents the way you would evaluate hiring a contractor: scope the work, run a real trial, and govern the access. Start by naming the task type you want to offload, then run one agent against it for a sprint or two and compare cycle time, rework, and review load against the prior period. Pay close attention to governance, because an agent that edits many files and routes code to an external model raises data-handling questions a completion plugin never did, and shadow adoption tends to outrun policy faster than leaders expect. The comparison below frames where each approach earns its place.
AI autocomplete
Agentic coding agents
Pair any agent rollout with real AI governance so access and model routing stay inside policy, and treat the trial as a measurement exercise rather than a popularity contest. The point is not to count how much code the agent produced. The point is to know whether your team shipped faster and safer because of it. For the morale side of measuring engineers in an agent-heavy world, see how to measure engineering velocity without morale loss.
Agents are good. The instrumentation is rare. Run the trial. Then prove it with cycle time.
FAQ
What are agentic AI coding tools?
Agentic AI coding tools are software agents that plan and execute multi-step coding work from a single instruction: they read context, edit files, run tests, and often open a pull request, instead of just autocompleting the next line. Cursor, Claude Code, GitHub Copilot agent mode, and Devin are common examples in 2026.
How are agentic coding tools different from AI autocomplete?
Autocomplete suggests the next line while a human drives. An agent takes an outcome and drives itself across many files, running and checking its own work. That shifts a larger share of authoring from the human to the model, which is why measuring human versus AI agent contribution becomes the harder problem.
What is the best agentic AI coding tool in 2026?
There is no single best. Cursor and Claude Code lead on in-editor agentic edits, GitHub Copilot agent mode wins on GitHub-native workflows, and async agents like Devin take an issue and return a pull request. The right pick depends on your codebase, your review capacity, and which one your delivery data rewards.
How do you measure ROI on agentic AI coding tools?
Connect agent usage to delivery output and watch the trend after rollout. Abloomify imports usage from Cursor, Claude Code, and GitHub Copilot, correlates it with PR cycle time and rework, and separates human from AI agent contribution PII-free, so a seat count becomes a defensible ROI number.
Reza Vatani
Co-Founder & CAIO
AI-driven entrepreneur with a strong background in robotics and advanced analytics. PhD from Old Dominion University and former Product Development leader at Nasdaq Verafin.