How to Reduce Context Switching and Improve Engineering Focus
June 3, 2026
Amir Tavafi
12 min read

Context switching happens when engineers toggle between projects, tools, channels, and meetings all day. The research most people quote is that it takes about 23 minutes to get back into deep focus after an interruption, and on an engineering team that number compounds fast: PR cycles stretch, bug rates climb, and code quality slips because nobody holds a problem in their head long enough to do it justice. Traditional project tools track tickets and tasks, so they miss the real cost, which is the mental gear shifting across Jira, Slack, GitHub reviews, and unplanned meetings that never shows up as a line item.
This guide covers how to spot context switching patterns on your team, measure their impact with signals you already generate, and reduce them with structural changes that protect focus. The measurement part matters most, because you cannot fix fragmentation you cannot see, and most leaders are flying blind on it.
Key Takeaways
Q: What is context switching in software development?
A: It is the cognitive cost of shifting between unrelated systems and rebuilding the mental model each time. Writing docs then writing code for the same service is fine. Jumping between a React frontend, a Python backend, and Terraform infra in one day is the expensive kind.
Q: Why does context switching hurt engineering teams so much?
A: Engineers do not lose seconds when interrupted, they lose the architecture they were holding in their head. That refocus tax (around 23 minutes per break) is why fragmented teams produce more bugs, shallower reviews, and stalled PRs even when everyone looks busy.
Q: How do you measure it without monitoring people?
A: Read work signals through APIs, not screens. Concurrent active projects, repository switches per day, time-to-first-commit after meetings, and the count of focus blocks longer than 90 minutes tell the story. No screenshots or keyloggers required.
Q: How do you actually reduce it?
A: Protect 90-minute focus blocks, cap work in progress, batch reviews and Slack, and contain interrupts with a rotating support role. Then use workforce intelligence to find which teams and project combinations create the most overhead.
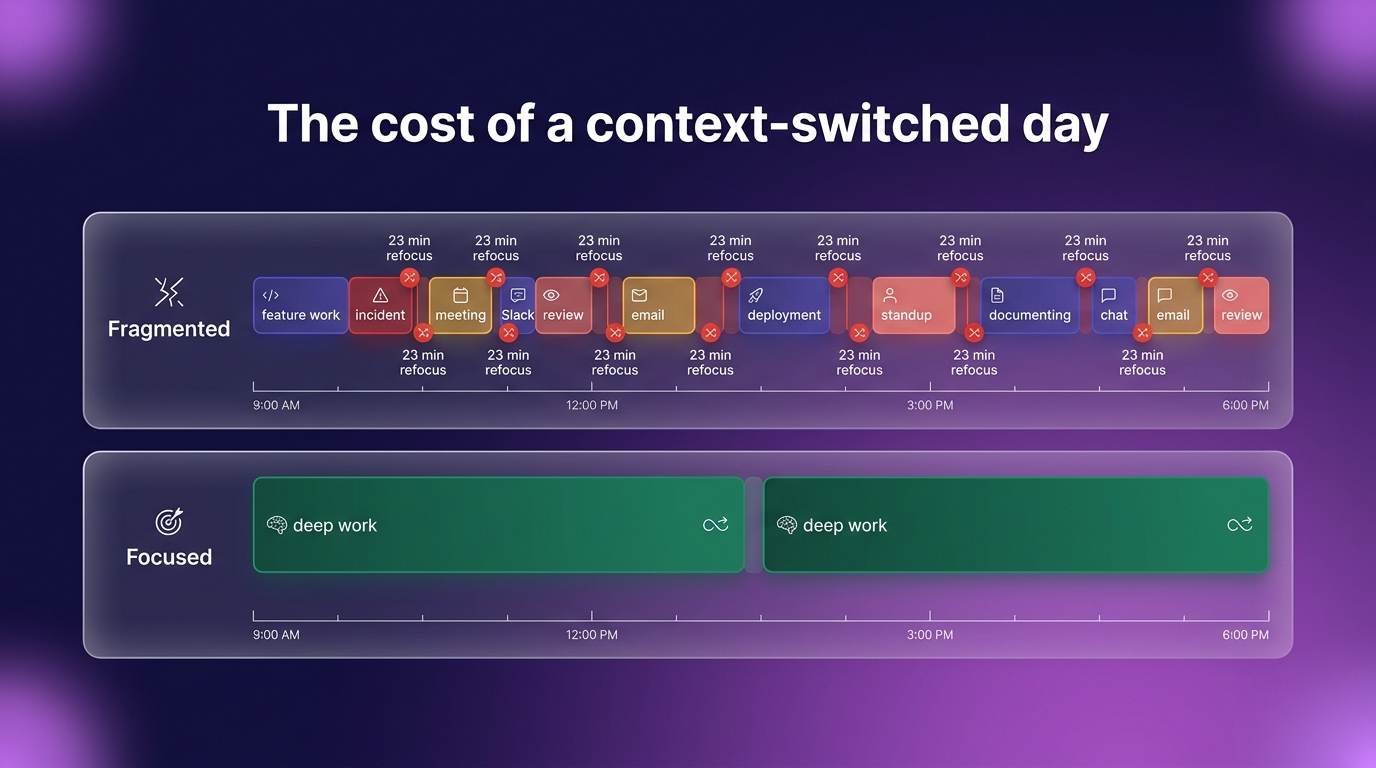
Why context switching destroys engineering productivity
When an engineer shifts between tasks, they do not just pause. They drop the mental model they built of the system they were working in, and each interruption forces them to rebuild it from scratch. That is why the 23-minute recovery adds up so quickly across a day full of pings and pop-ins.
The damage spreads past the individual. Teams with high context switching produce more bugs, because nobody can hold complex architectural detail in memory while juggling ten other things. Reviews get shallow because the reviewer is half in another problem. PRs sit idle longer because the author already moved on by the time feedback lands. The whole pipeline slows down while everyone appears fully occupied.
Most orgs measure output as story points completed or tickets closed, and those numbers hide the cost. An engineer who closes five tickets across ten contexts is less productive than one who closes four with full focus. The gap shows up later as technical debt, rework, and burnout, not on this sprint's chart. If you want the broader picture of which signals are worth trusting, our guide to developer productivity metrics covers which signals to track and which to ignore.
What is context switching in software development?
Context switching in software development is when engineers shift attention between different codebases, languages, architectural concerns, pull requests, bug fixes, and stakeholder requests. Unlike task switching, it requires reloading the mental model of a complex system every time.
A typical fragmented day looks like this: feature work in the morning, a production incident at noon, PR reviews after lunch, planning meetings in the afternoon. Each transition carries a cost that compounds. The authentication service someone was building before lunch gets swapped out for the payment bug they are chasing after it, and the morning's context is gone.
This is different from moving down a to-do list. Documentation and code for the same service keep the context consistent. The expensive version is holding several unrelated systems in your head at once, like a React frontend, a Python backend, and Terraform infrastructure all in the same afternoon.
The hidden costs of fragmented engineering work
Fragmented work creates technical debt, stretches cycle time, and accelerates burnout. Engineers spend more time reorienting than writing code. Half-finished features linger in draft PRs, merge conflicts pile up, and reviews get rushed.
Teams also lose flow state, which is where the hard architectural problems actually get solved. Flow needs at least 90 uninterrupted minutes, but most engineers report fewer than two such blocks per week. Without it, they default to shallow work like updating ticket status or answering messages instead of tackling the genuinely difficult parts.
The honest problem is attribution. When velocity dips, leaders cannot tell whether it is technical complexity, a skills gap, or fragmentation, so they reach for the lever they know. More engineers on a fragmented team usually means more coordination, more channels, and more switching, which makes the original problem worse.
How to measure context switching in engineering teams
Measuring context switching means analyzing work patterns across the systems where work already lives: GitHub, Jira, Slack, calendars, and repositories. The useful signals include active projects per engineer per day, time between commits on the same branch, meeting interruptions during coding hours, the number of Slack channels an engineer is active in, and PR review turnaround.
Privacy-first workforce intelligence aggregates these without invasive monitoring. The platform connects to the tools you already use and looks at patterns: when engineers jump between repositories, how much of the week goes to meetings versus coding, and how many simultaneous tickets a person is carrying.
This is the opposite of employee monitoring software that grabs screenshots or counts keystrokes. Instead of watching what an engineer does minute by minute, you look at aggregated patterns across tools to find structural problems. You learn that the team averages 4.5 concurrent projects per engineer. You do not learn that someone spent 12 minutes reading the news, and you should not want to. We go deeper on that distinction in measuring productivity without screenshots.
The metrics that reveal context switching patterns
Track concurrent active Jira tickets per engineer, average time-to-first-commit after meetings, repository switches per day, Slack response time during designated focus blocks, and PR review latency. Watch the ratio of planned work to unplanned interruptions. Count how often an engineer touches more than three codebases in a single day.
Analyze calendar fragmentation by counting uninterrupted blocks longer than 90 minutes. A healthy pattern is one or two projects with several two-hour focus blocks per week. An unhealthy one is five or more concurrent projects with nothing longer than 45 minutes. Commit patterns tell a similar story: frequent small commits on the same branch signal focus, while commits scattered across many repos and branches, with long gaps between them, usually mark forced switches to handle interruptions.
| Signal | Healthy | Fragmented |
|---|---|---|
| Concurrent active projects | 1 to 2 | 5 or more |
| Focus blocks over 90 min per week | 3 or more | Fewer than 1 |
| Repository switches per day | 1 to 2 | 6 or more |
| First review wait time | Under 4 hours | Over a day |
| Planned vs unplanned work | Mostly planned | Interrupt-driven |
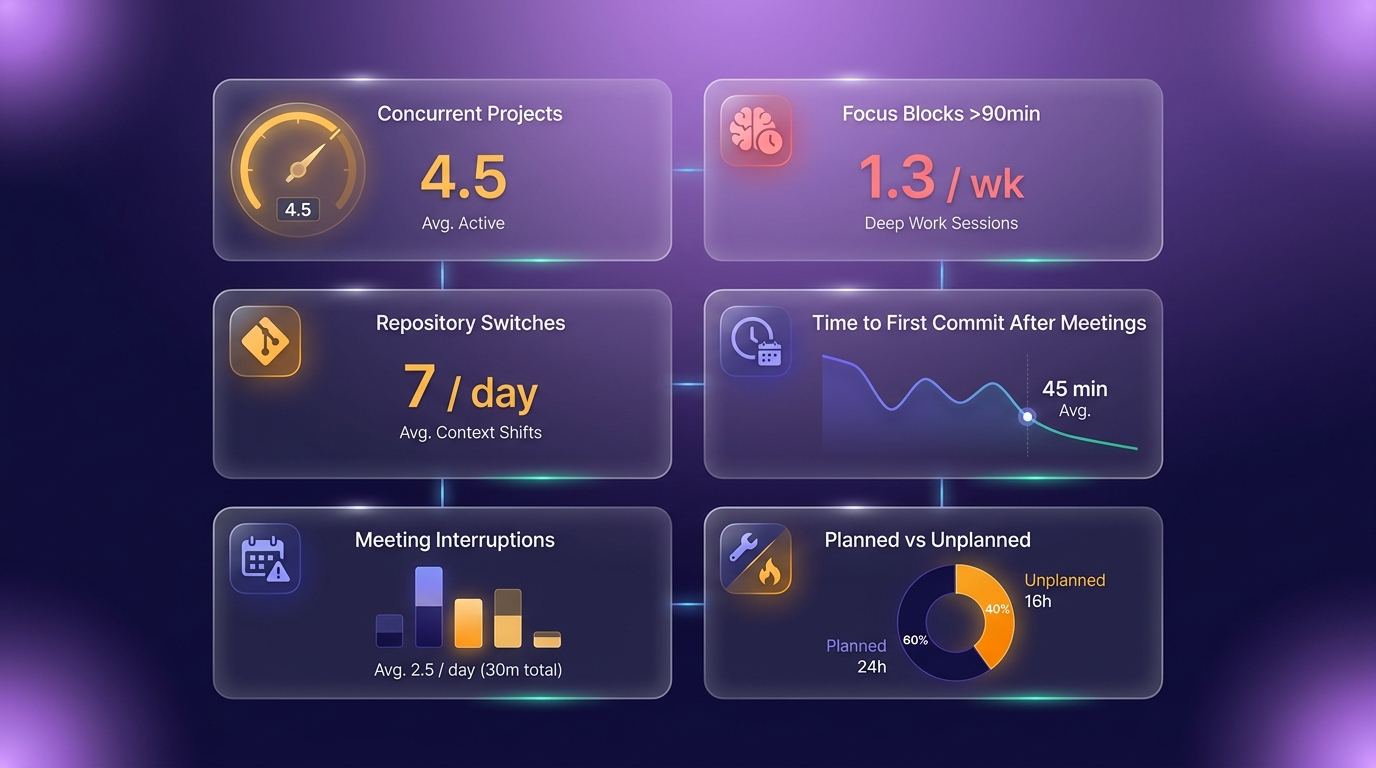
Using workforce intelligence to find fragmentation hotspots
Workforce intelligence platforms connect to GitHub, Jira, Google Workspace, Microsoft 365, and Slack to surface fragmentation that manual tracking misses. The analysis points to which teams carry the heaviest switching burden, which project combinations create the most cognitive overhead, and which meeting patterns shred focus time.
Leaders can ask Bloomy, the AI Chief of Staff, the questions they would otherwise spend a day pulling reports to answer:
- Which teams have the fewest 90-minute focus blocks this month, and what is eating them?
- Who is carrying four or more concurrent projects, and which ones could be sequenced instead of run in parallel?
- Which recurring meetings land in the middle of prime coding hours across the engineering org?
- Where is PR review latency highest, and is it a staffing problem or an interrupt problem?
The point is not a prettier dashboard. It is moving from a vague sense that the team is busy and slow to a specific, fixable cause. When you can see that a particular squad averages 4.5 concurrent projects and one focus block a week, the conversation stops being about effort and starts being about structure.
How to reduce context switching on engineering teams
Once you can see the pattern, the fixes are mostly structural and boring, which is a good thing. The four that move the needle:
- Protect real focus blocks. Defend at least two 90-minute blocks per engineer per day, on the calendar, treated as immovable. Half-protected time does not produce flow.
- Cap work in progress. Hold engineers to one or two active projects at a time and sequence the rest. Most fragmentation is just too much parallel work disguised as urgency. Our PR churn and WIP guide covers the right-sizing side of this.
- Batch reviews and communication. Reviewing PRs and clearing Slack in scheduled windows beats reacting all day. Same total work, far fewer interruptions to deep tasks.
- Contain interrupts with a rotating role. A single person on support or on-call absorbs the incidents and ad hoc requests so the rest of the team keeps their context. Rotate it so nobody burns out and everyone gets focus weeks.
Meeting hygiene sits underneath all of this. A handful of well-placed meetings beats a calendar sprinkled with syncs that each knock an engineer out of flow for the rest of the hour. If your team has tried meeting-free days and watched them quietly fail, what actually recovers deep work is worth a read, because the fix is rarely a blanket rule.

How Abloomify reduces context switching without surveillance
Abloomify connects to GitHub, Jira, Slack, and calendars through APIs and reads how work moves, never what a person types or reads. No screenshots, no keystroke logging, no screen recording. From those signals it builds the picture that matters for focus: concurrent projects, focus block availability, repository switching, meeting load during coding hours, and PR review latency, all at the team level.
Bloomy then turns that into something a leader can act on this week. It flags the squads losing focus time, names the project combinations creating overhead, and recommends specific changes, like sequencing two parallel initiatives or moving a recurring meeting out of prime coding hours. Because the data is PII-free and team-level, engineers can look at it without feeling watched, which is the only kind of productivity data a team will actually trust and improve against.
If you lead engineering and want clarity on where focus is leaking without putting a monitoring agent on anyone's laptop, that is exactly what Abloomify for engineering leaders is built to do. For the velocity side of the same data, see our guide to engineering velocity metrics.
FAQ
What is context switching in software development?
Context switching is when an engineer shifts attention between unrelated systems, such as a frontend React app, a backend Python service, and infrastructure code, and has to rebuild the mental model each time. It is heavier than task switching because the cost is reloading complex architecture into working memory, not just changing tools.
How much does context switching cost engineering teams?
Research puts the refocus cost at about 23 minutes per interruption, and fragmented work can reduce effective engineering velocity by 40 to 60 percent. The damage shows up as more bugs, slower PR cycles, and stalled features rather than in a velocity dashboard, which is why most teams underestimate it.
How do you measure context switching without surveillance?
You read aggregated work signals through APIs instead of watching screens. Abloomify connects to GitHub, Jira, Slack, and calendars and looks at patterns like concurrent active projects, repository switches per day, and focus blocks longer than 90 minutes. No screenshots, no keystroke logging, no screen recording.
What are the best ways to reduce context switching for engineers?
Protect real focus blocks of 90 minutes or more, cap work in progress so engineers carry one or two projects at a time, batch code reviews and Slack instead of reacting all day, and contain interrupts with a rotating on-call or support role. The goal is fewer forced mental gear shifts, not more hours.
Can workforce intelligence find which teams are most fragmented?
Yes. Abloomify aggregates signals across your tools to show which teams carry the highest context switching burden, which project combinations create the most overhead, and which meeting patterns shred focus time. Bloomy, the AI Chief of Staff, surfaces those hotspots so leaders can fix the structure, not blame individuals.
Amir Tavafi
Co-Founder & CEO
Product leader and innovator with over 15 years of experience in the tech sector, grounded in AI and robotics. Previously led product development in fraud detection and AI solutions at Nasdaq Verafin.