Code Churn: What It Is and How to Measure It in 2026
June 16, 2026
Reza Vatani
10 min read

Code churn is the share of recently written code that gets rewritten, reverted, or deleted within a few weeks of being committed. A little churn is healthy iteration. A lot of it, especially right after a feature ships, signals rework, unclear requirements, or AI-generated code nobody fully owns. Abloomify reads code churn from GitHub, GitLab, and Bitbucket as a work signal, without reading the code itself.
Key Takeaways
Q: What is code churn in simple terms?
A: Code churn is how much of your recently written code gets thrown away or rewritten soon after it lands. It measures rework, not effort. Abloomify tracks it from Git history as a delivery signal alongside PR cycle time and review health.
Q: Is code churn always bad?
A: No. Early-stage features and hard problems churn, and that is normal iteration. Churn becomes a problem when it stays high after code ships, climbs across sprints, or concentrates in a few files. The trend tells you more than any single number.
Q: How does AI coding affect code churn?
A: AI assistants like Cursor, GitHub Copilot, and Claude Code generate plausible code quickly, and a meaningful share of it gets reverted. GitClear's analysis of over 150 million changed lines found churn rising as AI adoption grew. Separating human from AI agent contribution shows where.
Q: Can you measure code churn without spying on developers?
A: Yes. Abloomify connects to GitHub, GitLab, Bitbucket, and AI coding tools through APIs and reads signals, not code content or screens. No screenshots, no keyloggers. You get churn rate, rework, and human vs AI agent contribution from data engineers already produce.
What is code churn?
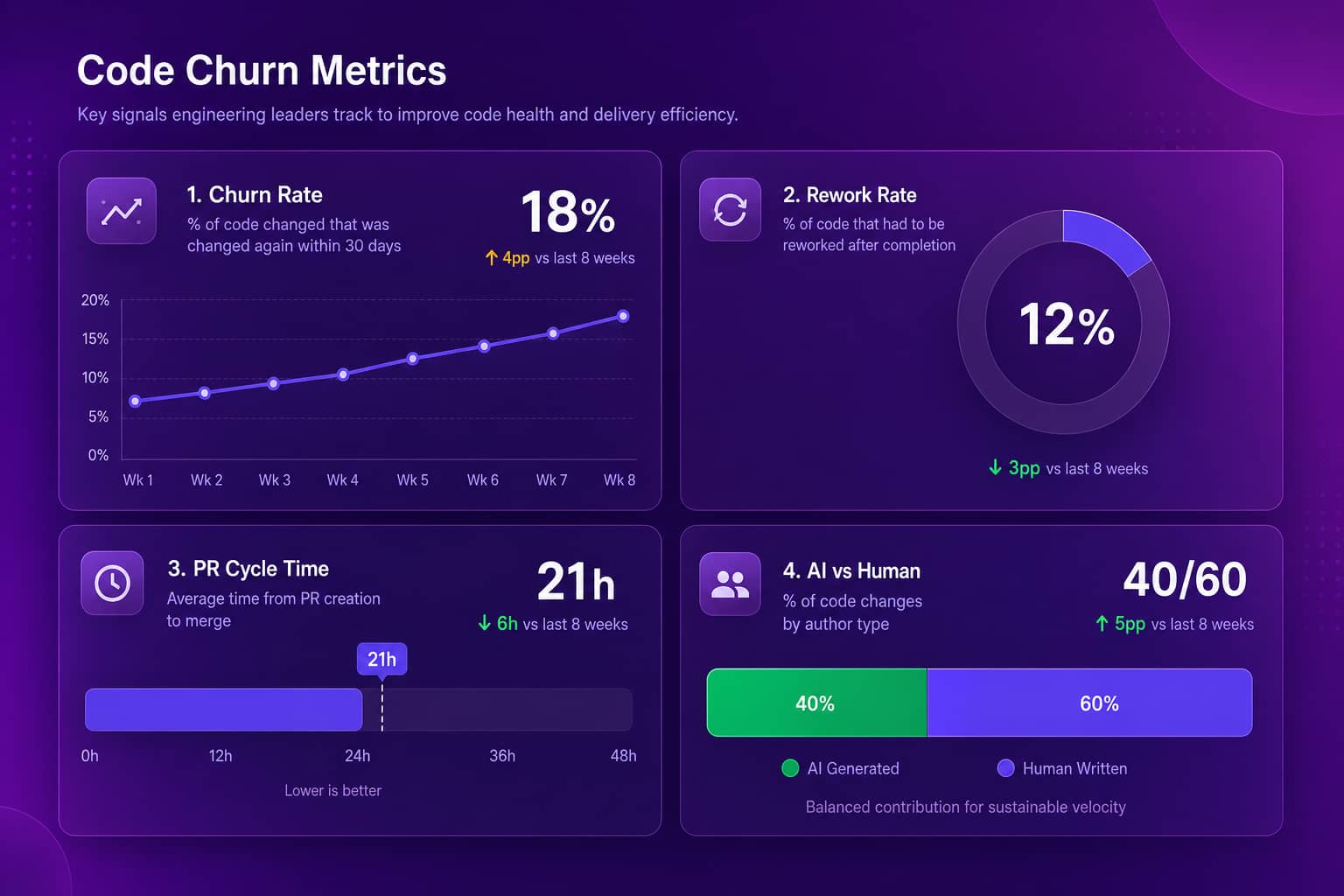
Code churn is the percentage of code that gets rewritten, reverted, or removed shortly after it was written, usually inside a two-to-three-week window. It is a rework signal. When an engineer commits a feature on Monday and half of it is gone by the next sprint, that deleted and modified code is churn. Git already records every line added, changed, and removed, so churn is one of the few engineering metrics you can measure precisely without asking anyone to log anything. The point is not to drive churn to zero. Early exploration churns, and that is how good software gets built. The point is to see the pattern: which teams, which files, and which kinds of work churn the most, and whether that number is trending up.
Most engineering analytics vendors, from LinearB to Jellyfish to CodeScene, track some version of this because it correlates with delivery pain better than commit counts or lines shipped. Churn is harder to game than activity metrics. You cannot inflate it by typing more.
How do you calculate code churn?
You calculate code churn by measuring the lines of code that touch recently written code, then dividing by total lines changed over the same period. The standard window is the last two to three weeks, because that captures rework while filtering out healthy long-term refactors of old, stable code. A line written six months ago and refactored today is maintenance. A line written nine days ago and rewritten today is churn. Pulling this from Git is straightforward, but doing it cleanly across many repos, mapping commits to people and teams, and excluding generated files and vendored dependencies is where most homegrown scripts fall over.
A workable formula:
- Churn rate = (lines added + modified + deleted on recently written code) / (total lines changed in the period)
- Window: trailing 2 to 3 weeks, so refactors of old code are not counted as churn
- Granularity: per engineer, per team, per repo, and per file path, so spikes are findable
- Pairing: read churn next to PR cycle time and review depth, never alone
Abloomify computes churn from GitHub, GitLab, and Bitbucket and ties it to engineering productivity analytics like PR cycle time and review health, so a churn spike comes with the context to explain it.
What is a healthy code churn rate?
There is no universal healthy code churn rate, and anyone who quotes you a single percentage is selling something. Most teams land in the low-to-mid double digits as a share of changed code, but the absolute number depends on language, project maturity, and how much greenfield work is in flight. What matters is the trend and the distribution. A stable churn rate with occasional spikes when the team tackles a hard, ambiguous problem is a sign of normal iteration. A churn rate that climbs steadily across three or four sprints, or that clusters in one service or one engineer's work, is the signal worth a conversation. Read the shape, not the headline number.
| Churn pattern | What it usually means | Action |
|---|---|---|
| Low and stable | Mature code, clear scope | Leave it alone |
| Spikes during hard features | Healthy exploration | Expected, no action |
| Rising across sprints | Scope creep or unclear requirements | Tighten specs and design review |
| Concentrated in one service | Fragile module or tech debt | Targeted refactor |
| High right after merge | Rushed review, weak testing | Slow the merge, deepen review |
Why code churn matters for delivery
Code churn matters because it is rework, and rework is the quietest tax on engineering velocity. A team can post strong commit counts, healthy story-point burndown, and busy GitHub graphs while quietly rewriting a third of what it ships. None of the usual dashboards catch this, because activity metrics reward motion. Churn catches it because it measures the work that did not stick. High sustained churn shows up later as missed dates, brittle releases, and the demoralizing experience of building the same feature twice. It also distorts every other metric you trust: velocity looks fine, but a chunk of that velocity is undoing last sprint's velocity.
This is why churn belongs next to developer productivity metrics like PR cycle time and review health, not in a silo. Churn tells you how much of the output was real. The 50-person SaaS team that first validated Abloomify's engineering data against a manual spreadsheet cared about exactly this: they wanted numbers that matched what they felt on the ground, not a prettier activity chart.
Is AI increasing code churn?
For many teams, yes, AI coding tools are pushing code churn up. GitClear's analysis of more than 150 million changed lines of code found that as AI assistants were adopted, the share of churned and duplicated code rose rather than fell. The mechanism is intuitive. Tools like Cursor, GitHub Copilot, and Claude Code are very good at producing code that looks right and reads confidently, fast. That confidence is exactly the risk when the code gets reverted two weeks later. AI lowers the cost of generating a first draft, which means more first drafts ship, which means more of them get rewritten once a human actually owns the consequences.

This is the part most tools miss. If you cannot separate what humans wrote from what an AI agent generated, you cannot tell whether your Copilot rollout is shipping leverage or shipping rework. Abloomify separates human vs AI agent contribution across tasks, code, and reviews, then ties it back to churn and AI coding tool ROI. The goal is not to slow AI down. The goal is to see where AI-generated code churns so you can fix the review and prompting around it. Trust the tools. Measure the output.
How to measure and reduce code churn without surveillance
You reduce code churn by tightening the front of the pipeline, not by watching the people at the end of it. Most churn traces back to unclear scope, oversized pull requests, and reviews that wave code through. Smaller diffs, sharper requirements, and deeper review on high-churn paths do more than any monitoring tool ever will. The measurement should follow the same principle: read the work signals, not the screens. Abloomify connects to GitHub, GitLab, Bitbucket, Jira, Linear, and AI coding tools through APIs and reports churn rate, rework, PR cycle time, review health, and human vs AI agent contribution. PII-free by architecture: no screenshots, no keyloggers, no screen recording, no reading of code content.
A few moves that actually lower churn:
- Right-size pull requests. Large diffs hide churn and get rubber-stamped. See how to reduce PR churn.
- Deepen review on high-churn paths. Point review effort where the data says rework concentrates.
- Tighten scope before code. Most churn is a requirements problem wearing a code costume.
- Watch AI-generated churn specifically. Separate human from AI agent output so the rework is attributable.
Churn is a mirror. It shows you how much of your team's speed is real and how much is rebuilding what already shipped. Measure it honestly and the rest of your velocity numbers start telling the truth too.
FAQ
What is the difference between code churn and PR churn?
Code churn measures recently written code that gets rewritten or deleted, usually within two to three weeks, across the whole codebase. PR churn is narrower: it tracks how much a single pull request changes while it is open in review. Both signal rework. Abloomify reports both alongside PR cycle time so you can see where iteration turns into redo.
Is high code churn always a problem?
No. Greenfield features, prototypes, and genuinely hard problems churn, and forcing that to zero would just push exploration out of the codebase. High churn is a problem when it stays elevated after code ships, rises across multiple sprints, or concentrates in one service or person. The trend and the distribution matter far more than any single percentage.
How does Abloomify measure code churn?
Abloomify connects to GitHub, GitLab, and Bitbucket through APIs and computes churn from commit history, mapped to engineers, teams, repos, and file paths. It reads work signals, not code content, and pairs churn with PR cycle time, review health, and human vs AI agent contribution. No screenshots, no keyloggers, no screen recording.
Can tracking code churn hurt team trust?
It can if you wield it as a surveillance number or rank individuals by it. Used well, churn is a team-level health signal that points to scope and review problems, not people problems. Abloomify's engineering productivity analytics are PII-free by design so the conversation stays about the work, not about who to blame.
Reza Vatani
Co-Founder & CAIO
AI-driven entrepreneur with a strong background in robotics and advanced analytics. PhD from Old Dominion University and former Product Development leader at Nasdaq Verafin.